前言
企業中生產管理系統MES和實驗室管理系統LIMS經過了長時間的應用,積累了海量的數據,但這些海量MES數據、LIMS數據并不全是對企業有價值的數據。因此,讓MES、LIMS中的海量數據通過合理篩選成為對企業有價值的大數據、即讓MES和LIMS系統中的大數據產生關聯性及更大的額外價值,進而進行數據分析和決策成為企業業績增長的根本。而MES、LIMS的海量數據篩選、數據分析、數據決策需要大量的數據統計學、機器學習的知識,數據大腦與MES和LIMS等系統的融合應用可以有效降低應用難度。
當測試的數據不是一個單向的期望值,不能用“越怎么樣越好”來表述的時候,可以考慮用符號檢驗來測試。如果通過平均值來測試一組樣品,在以平均值為參考時,很難評價這一組樣品哪個好,哪個不好,因為即使存在個體差異很大的情況,也能和期望平均值接近。所以要用另外一種方式,把這一組樣品數據,轉換成“越怎么樣越好”的思維模式,比如說越接近期望值越好,這個檢驗方式就是符號檢驗。
案例
假設一位化工工程師想確定一組不銹鋼樣本中的平均錳含量是否等于18%,這位工程師隨機選擇了12個樣本并測量了錳含量。
工程師執行了單樣本符號檢驗,以確定平均錳含量是否不等于18%。
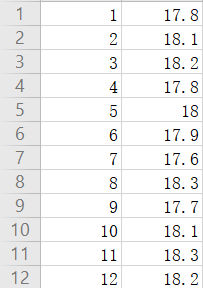
圖1樣本數據
分析過程
從數據大腦中的組件面板查找Excel讀取組件,拖動到工作面板,配置資源、輸出、文件路徑、隊列容量。

圖2 Excel讀取組件配置
從數據大腦中的組件面板查找單樣本符號檢驗組件,拖動到工作面板,配置輸入、樣本、檢驗中位數、隊列容量。點擊運行,從調試中查看結果。
圖3單樣本符號檢驗組件配置
分析結果
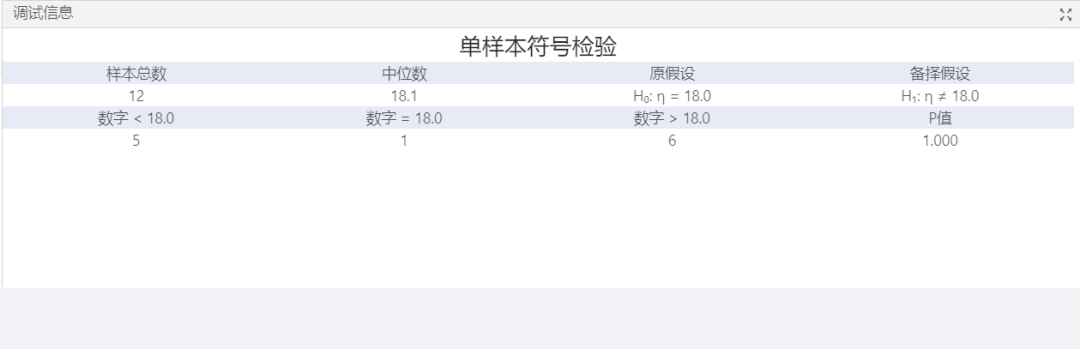
圖4調試信息
根據結果可以看到數據中一共有12個樣本,中位數為18.1。原假設的理想值為18,<18的有5個,>18的有6個,=18的有1個。由于p值為1(大于顯著性水平0.05),因此原假設成立。
與LIMS系統相融合
將數據大腦單樣本符號檢驗與國工實驗室智能研發管理系統(LIMS)相融合,在檢驗實驗樣本時,能提高準確性,可以避免樣本個體差異過大的情況,從而更加準確地判斷出被檢測樣本是否符合期望標準。
含義
使用單樣本符號檢驗組件可以估計總體中位數并將它與目標值或參考值進行比較。使用此分析,可以執行以下操作:
1.確定總體中位數是否不同于您指定的假設中位數。
2.計算可能包括總體中位數的值范圍。
參數說明
1. P>0.05表示無顯著性差異。2. 0.01<P<0.05表示顯著性差異。3. P<0.01表示極顯著性差異。
適用范圍
為了確保結果有效,請在收集數據、執行分析和解釋結果時考慮以下準則:
1.數據不來自對稱分布。
2.數據不必是正態分布的。
3.樣本數據應該是隨機選擇的。
4.每個觀測值都應當獨立于其他所有觀測值。

國工智能是一家專業為流程制造業提供人工智能決策控制整體解決方案及落地服務的國有參股高新技術企業,專注于利用人工智能、大數據等技術解決流程制造業海量數據下復雜場景的智能制造需求,為客戶提供“IOT+AI+OR”智能制造人工智能整體解決方案。目前,公司已經成為化工新材料行業人工智能決策控制領域的領跑者。
作為一家國內專業的智能制造落地服務商,國工智能憑借深厚的內功和優秀的團隊,自主研發了基于人工智能的數據大腦分析平臺(MAI)、智能制造管理平臺(MES)、物聯網數據采集平臺(SCADA)、實驗室管理系統(LIMS)、雙體系設備管理系統(EMS),均在行業內成功應用。
責任編輯:胡金鵬



