作者:國工智能實施團隊—左鵬
前言
近年來,數據挖掘引起了信息產業界的極大關注,其主要原因是企業在生產、運營過程中產生大量的數據,迫切的需要將這些數據轉換成有用的信息和知識。獲取的信息和知識可以廣泛用于各種應用,包括商務管理,生產控制,市場分析,工程設計和科學探索等。
國工智能實驗室LIMS系統融合了國工智能數據大腦平臺,平臺內提供上百種統計學相關算法及機器學習算法;通過這些算法對企業數據進行分類分析、聚類分析、關聯分析、預測分析,挖掘數據潛在價值,探索人力無法探知的規律,提高企業產品附加值及行業競爭力,助力企業快速發展。本次案例就雙樣本Poisson檢驗與實驗室LIMS系統相融合進行探討及應用舉例。
案例
某企業質檢實驗室需要檢驗A、B兩種實驗樣品的缺陷數量,在相同的檢驗方案條件下分別用A、B兩種實驗樣品進行檢驗,得到的檢驗結果如圖1所示,試分析在相同檢驗方案情況下,A、B兩種實驗樣品的缺陷出現率。
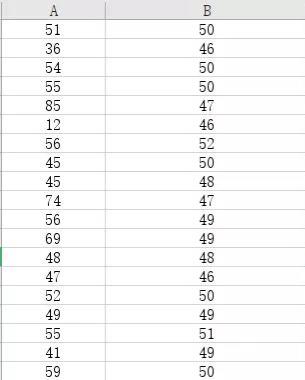
圖1檢驗結果
分析過程
使用國工數據大Excel讀取組件,將數據集映射到系統中。
圖2 Excel讀取
再通過拖拽的方式將雙樣本Poisson率檢驗分析組件與Excel讀取鏈接到一起。使用集成好算法的雙樣本Poisson分析組件進行數據的Poisson分析處理,對組件參數進行設置,因素字段配置為factor,結果值配置為檢驗結果result,顯著性水平設置為0.05,單擊運行,從調試面板中查看分析結果。
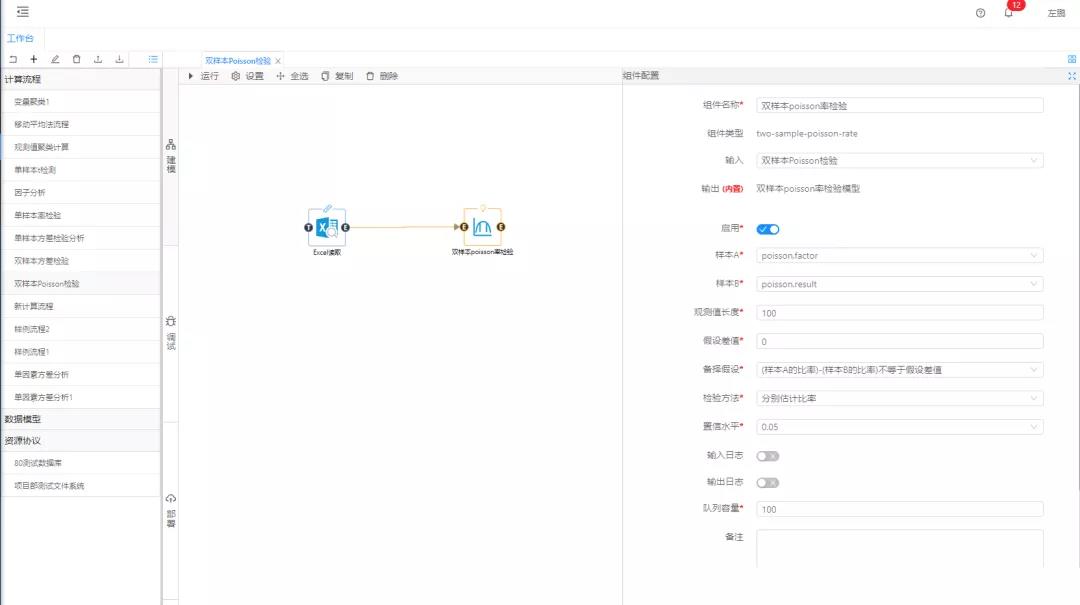
圖3雙樣本Poisson率校驗分析組件及參數配置
分析結果
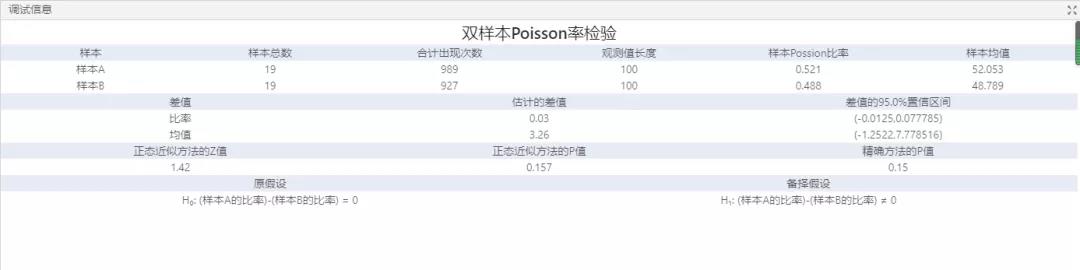
圖4分析結果
從圖4中運用雙樣本Poisson分析得出的結果可以看出,由于p 值0.157大于顯著性水平(用α 或alpha表示)0.05,因此分析員否定原假設并得出兩個樣本缺陷發生率不同的結論。95%置信區間表明,樣本B 的缺陷率可能高于樣本A 的缺陷率。
與LIMS系統相融合
國工數據大腦平臺可直接獲取實驗室LIMS系統中的實驗數據,直接將實驗數據對接到創建好的雙樣本Poisson檢驗模型中,根據得出的分析結果自動對報告進行判定,代替人工判定;并將存在缺陷顯著性差異的報告重點推送給相關領導引起重視。根據領導對存在顯著性差異報告的處理,可自動觸發二次檢驗流程等操作。
含義
實驗室系統中的雙樣本Poisson檢驗用于比較兩個遵循Poisson分布的總體的均值或發生率以確定它們是否存在顯著差異的假設檢驗。Poisson分布可為時間在給定時間內發生次數、面積、體積或其他觀測空間建模。
適用范圍
·確定兩個組的總體發生率是否不同。
·計算可能包括總體率之間差值的值范圍。
例如,實驗員檢查2 個批次(A和 B)上每箱實驗樣本的缺陷數量。一個樣品可能會有多個缺陷,對于批次A,每箱包含10個樣本。實驗員總共抽取50箱,共發現122個缺陷。對于批次B,每箱包含15個毛巾。實驗員總共抽取50箱,共發現132個缺陷。
對于批次A,總發生次數為122,原因是實驗員發現了122個缺陷。對于批次B,此數字為132,原因是實驗員發現了132個缺陷。
對于這兩個批次,樣本數量(N)均為50,原因是實驗員對于這兩個批次均抽取了50箱。
為了確定每個樣本的缺陷數,實驗員對批次A 使用觀測值長度10,原因是每箱有10個樣本。對于批次B,檢查員使用觀測值長度15。
對于批次A,采樣率為(總發生次數/ N)/(觀測值長度)= (112/50) / 10 = 0.224。對于批次B,采樣率為(132/50) / 15 = 0.176。因此,批次A 中每個樣本平均有0.244個缺陷,批次B 中每個樣本平均有0.176個缺陷。
由于實驗員輸入的觀測值長度不為1,因此數據大腦也將計算樣本均值。對于批次A,樣本均值為(總發生次數/ N)= 112/50 = 2.24。對于批次B,樣本均值為132/50 = 2.64。樣本均值描述每箱的平均缺陷數。但是,由于各箱中含有不同數量的實驗樣本,因此采樣率是更有用的統計量。
責任編輯:殷守龍



